
{kind=link}
早陣子 NVIDIA RTX 40 系列搶盡鋒頭,AMD 全新 RNDA 3 架構的 Radeon RX 7900 系列新卡,既是首款採用 Chiplet 設計的 Gaming GPU,開價又比假想敵 RTX 4080 便宜,到底實際效能是否足以挑戰對手?以下先從 Radeon RX 7000 系列 GPU 改用全新RDNA 3架構,應用 Chiplet 設計說起。
快速導讀:
Part 1:Chiplet 設計!Radeon RX 7000 系列 GPU RDNA 3 架構分析
Part 2:挑戰 RTX 4080!AMD Radeon RX 7900 XT/XTX 開箱速覽
Part 3:效能對決!RX 7900 XT / XTX 挑戰 RTX 4080

AMD 早已於 Ryzen CPU 應用 Chiplet 設計,將 Core Complex Die 與 I/O Die 分別以不同製程生產、再封裝在單一晶片上,有助提升生產良率,並降低成本。RDNA 3 GPU 主要分為 Graphics Compute Die(GCD)與 Memery Cache Die(MCD)兩部分晶片,當中 GCD 採用 5nm 製程生產,MCD 則為 6nm 製程;AMD 稱 MCD 包括的 Infinity Cache 與 GDDR6 記憶體介面,未能受惠於 5nm 製程,改用成本較低的 6nm 製程將更加合適。
5nm GCD + 6nm MCD組合
GCD 與 MCD 兩者之間採用全新 Infinity Links 連接,官方數字稱 Chiplet Interconnect Bandwidth 高達 5.3TB/s(此數字是由 GDDR6 記憶體介面加上第二代 Infinity Cache 的峰值頻寬),足足以 RDNA 2 的 2.7 倍。Chiplet 設計無可避免會帶來額外的延遲值,AMD 的彌補方式是提升 RDNA 3 晶片的運作時脈,當中 Fabric 提升43%、GPU Game Clock 提升 18%,結果 RDNA 3 的記憶體延遲值比上代還要降低10%。




完整規格之 RDNA 3 GPU,由一組 GCD 與 6 組 MCD 組成,當中 GCD 晶片面積為300mm2;每組 MCD 則為 37mm2 面積,包含 16MB 容量之 Infinity Cache。整顆 GPU 的電晶體數目高達 577 億個,較上代的 268 億高出一倍以上。
CU 單元全面升級
RNDA 3 架構的 Compute Unit(CU)大幅改動,當中 Vector Unit 於單一周期下,可執行一個 Wave 64 FMA 指令,或者兩個 Wave 3 2指令(1 Float + 1 Int 或 2 Float),因此於特定應用場景下,可理解為單一周期可執行兩個指令。AMD 官方規格並沒有直接將 SP(Stream Processor)數字列成雙倍,因此 RX 7900 XTX 的 SP 數目為6,144個(而非 12,288 個)。但官方公布之理論浮點運算能力(RX 7900 XTX 單精度為 61 TFLOPS,上代 RX 6950 XT 則為 23.65 TFLOPS),正是運用 Dual Issue SIMD 才能得出,否則不可能達到上代的 2.6 倍之譜。
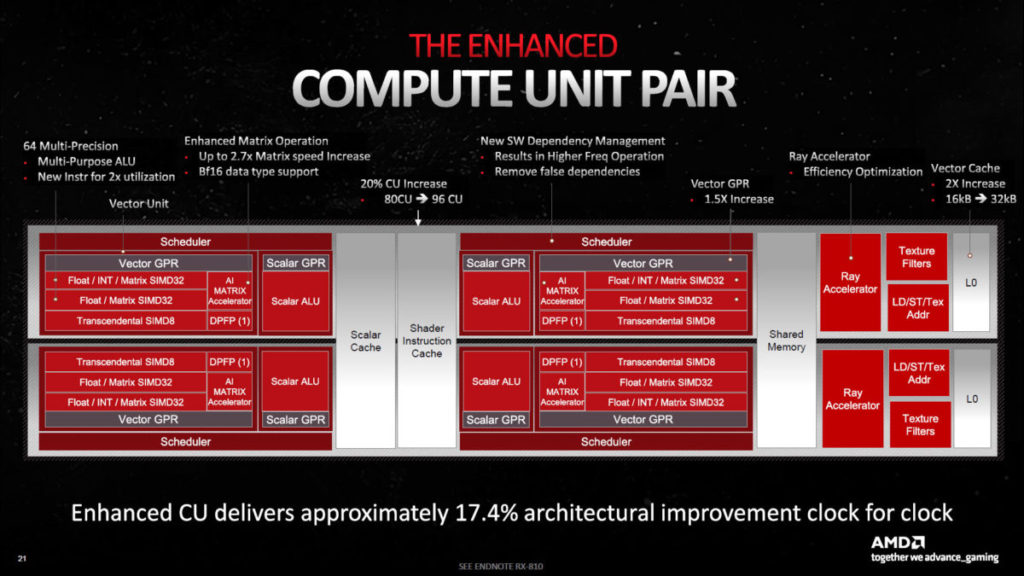

每組 CU 特地加入兩個 AI Accelerator,號稱提供上代的 2.7 倍 AI 吞吐量。Ray Tracing Accelerator 亦升級為第二代,號稱比上代提速達 80%。今代 GPU 運作時脈改用 Decoupled clocks,當中 Shader 時脈高達 2.3GHz,Front End 時脈則可達 2.5GHz,官方稱可達到效能與耗電水平的更佳平衡。


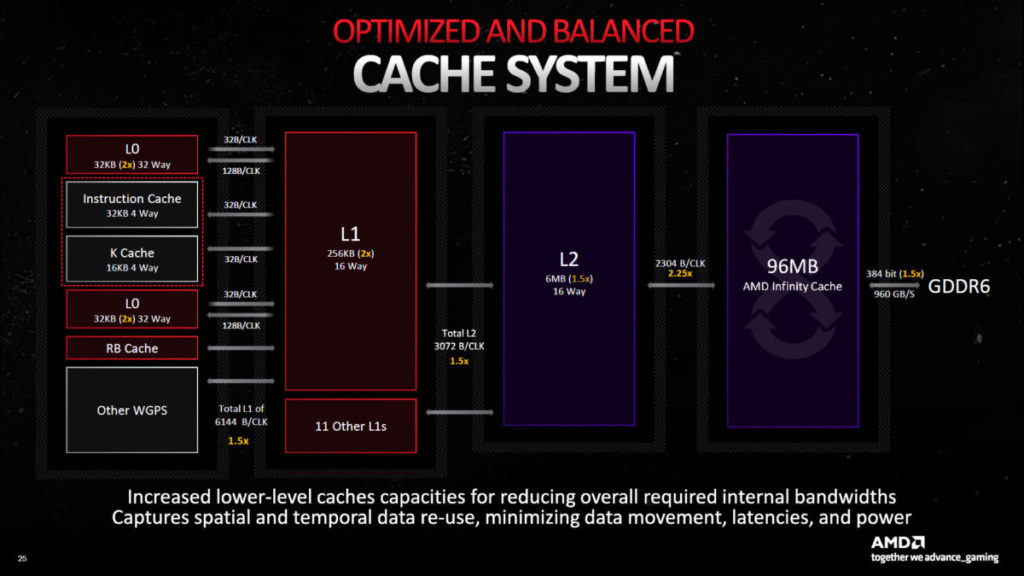
RDNA 3 的 Cache System 全面提升,當中每組 L0 Cache 增至 32KB、較上代多一倍,L1 Cache 增至 256KB、較上代多一倍,L2 Cache 增至 6MB、是上代的 1.5倍。L0 與 L1之間的頻寬、L1 與 L2 之間的頻寬,均為上代的1.5倍,L2 與 Infinity Cache 之間的頻寬更是上代的 2.25 倍。不過,Infinity Cache 容量由上代的 128MB 縮減至 96MB,相信 AMD 是以更高頻寬彌補容量的損失。

輸出、編碼能力躍進
RDNA 3 著力提升顯示輸出能力,命名為 AMD Radiance Display Engine,率先支援 DisplayPort 2.1 介面,理論頻寬高達 54Gbps,對應 12bit-per-channel、最高顯示 680 億種色彩,更可對應 1,440p@900Hz、4K@480Hz 以至 8K@165Hz 之超高刷新率。

RNDA 3 GPU 內建兩組 Media Engine,可同時進行兩項編碼或解碼工作,支援 H.264、H.265、VP9 與 AV1 格式之解碼,以及 H.264、H.265 與 AV1 格式之編碼。當中 AV1 最高支援至 8K60 解像度之解碼及編碼,號稱運作速度是上代 1.8 倍。
